AbemaTVのインターンで動画データの管理コストを削減した話
 お久しぶりです.いとゆうです.
お久しぶりです.いとゆうです.
毎日寒くて嫌になります.京都の気候は,夏が暑くて冬が寒いというのはよく言われることですが,ほんとに住むには向かない場所だなぁ…とつくづく思います.私は寝起きの寒さにとことん弱い人間なので,起床時間の1時間前くらいに暖房を入れるようにしていますが,それでもお布団の呪縛から逃れるのは至難の業です.
さて,前置きはこのくらいにして,先日CyberAgentさんのインターン「JOB」に参加してきました.CAさんのインターンは夏にも参加させていただいたのですが,今回参加したJOBは実際の開発現場で1ヶ月働く就業型のインターンになります.勤務頻度は最低週3から選ぶことができ、私は就活と並行して進めたかったため週3で勤務しました。なので実質的な勤務日数は10日程度になります。
配属された部署
配属されるサービスや部署は,選考時にどんな経験がしたいかを伝えることで,それに合わせて決めてもらえます.私の場合は,「大規模なサービス」の「クラウドインフラ」を触りたいという希望を伝え,結果としてAbemaTVの動画運用の効率化や動画管理コストの削減を担っているContents Engineeringチームに配属となりました.
以下の内容は、Contents Engineeringチームの方々に許可をいただいて執筆しています。
AbemaTVのメディアアセット管理
今回担当したタスクについて説明する前に,まずAbemaTVの動画データやサムネイル画像などのメディアアセット(以後、アセット)の管理がどのようにして行われているかを説明する必要があります.
もともとAbemaTVでは,他社から納品,または自社で収録されたアセットを磁気テープに保存して管理していました.これがテレビ局でも一般的に用いられている管理方法だそうです.このようなアナログな管理方法をとっていた理由としては,クラウドストレージで管理しようとした場合の維持コストの大きさです.
しかし,コスト以外の冗長性や柔軟性なども含めて判断した結果,現在ではフルクラウドでの管理に移行してきています*1.
実際の管理方法について,詳しいことはお伝えできませんが,アセットを一元的に管理するための社内ツールが存在します.この社内ツール経由で,納品されたアセットをクラウドにあげて管理しています.
担当したタスク
さて,前節にて,クラウドでのアセット管理はコストがかかるということをお伝えしました.今回は,このクラウドでの管理コストを抑えるため,素材管理の社内ツール上でゴミ箱フォルダに投下されたアセットやフォルダ、およびそれらのメタデータを,投下から1週間経過後に削除するバッチの実装を行いました.大まかな仕組みは下図のようになります。
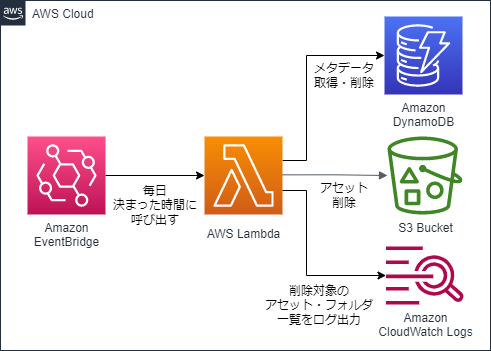
インフラ構築
上の構成図に沿って、AWSのインフラをTerraformで構築しました。Terraformは、JSONのようでJSONでないHCLというフォーマットで、AWSやGCPなどのインフラをコードとして構築できるツールです。
今回は、以下のリソースをTerraformで構築しました。
- EventBridge(Cloudwatch Event)
- Lambda
- ECR Repository(Lambdaのもとになるコンテナイメージのデプロイ用)
- IAM Role(LambdaにS3やDynamoDBへのアクセス権限を与えるため)
また、DynamoDBのテーブルに対し、グローバルセカンダリインデックス*2を新しく定義しました。この理由としては、主キー以外の属性に基づいて検索を行う必要があったためです。
DynamoDBの仕様上、テーブルに対してクエリで検索をかける際、非キー属性の値に基づいて検索をすることができません*3。今回、ゴミ箱投下から1週間以上経過したデータを検索するにあたり、非キー属性の値を条件として用いる必要がありました。
そこで、検索に用いたい非キー属性を主キーとしたグローバルセカンダリインデックスを新しく定義し、このインデックスに対してクエリを発行することで検索を可能にしました。
削除のロジック
アセット・フォルダを削除する際のロジックですが、これがなかなかに複雑でした。単純にクエリで取得したデータを削除して終わりではありません。
まず、DynamoDBに対してクエリを叩き、ゴミ箱フォルダに投下されてから1週間以上が経過したアセット・フォルダのメタデータを全て取得します。そこから更に、それぞれのアセット・フォルダの親フォルダを辿り、親フォルダもまた削除していいフォルダであるか(ゴミ箱投下から1週間経過しているか)を確認します。さらにその親フォルダを...と繰り返し、最終的にゴミ箱フォルダに行き着いた時点で、これまで辿ってきた親フォルダも含めてアセット・フォルダを削除します。
文字だけだと分かりづらいので、あるアセットAに対する削除ロジックを図解すると下のような感じです。

ここで、「なぜこんな複雑なことをするのか。クエリで取得した時点でゴミ箱の中に入っていることは分かっているのでは?」と思う方もいると思います。ここまで複雑な実装をする理由としては、メタデータに不整合がある可能性を考慮してのことでしょう。
例えば、私個人の推測になってしまいますが、一度ゴミ箱に入れたアセットを外に出した際、メタデータの更新がうまくいかずにステータス上はゴミ箱配下になってしまうケースです。クエリで返ってきたものをそのまま削除する実装だと、こうした不整合データを誤って削除してしまうリスクがあります。
学び
今回のインターンでは、経験の浅いクラウドインフラに関するタスクをメインに振っていただいたこともあり、インフラ面で多くのことを学ぶことができました。ここでは、下の3つのトピックについてまとめたいと思います。
- IaC、GitOpsという考え方について
- AWS DynamoDBについて
IaC、GitOpsという考え方について
IaC(Infrastructure as Code)とは
仮想化環境やクラウド環境においてインフラの定義をコードとして記述し、管理する考え方です。最近はクラウドインフラでサービスを運用するケースが増えており、サーバやデータベースといったリソースの実体を意識することが少なくなってきました。こうした背景を受け、リソースの実体を意識せずにインフラの設定や管理を効率的に行うための1つのプラクティスがIaCです。
運用者はリソースの構築や設定に必要な手続きを意識することなく、単に「このリソースを」「この設定で」用意したいと宣言的に記述していくことで、IaCのツールが自動的にインフラ構築を行ってくれます。分かりやすい例としては、Docker ComposeのComposeファイルです。実際はTerraformやCloudFormationといったクラウドインフラのIaCツールが用いられることが多いですが、Docker Composeも仮想化環境における1つのIaCの形だと思います。
resource "aws_instance" "web" {
ami = data.aws_ami.ubuntu.id
instance_type = "t3.micro"
tags = {
Name = "HelloWorld"
}
}
メリット
インフラの再現性が向上
手動でのインフラ構築は手順が煩雑化しがちなため、他者が同じインフラ環境を再現することは困難です。しかしIaCであればインフラを定義したコードを共有することで、他者でも容易に環境の再現が可能です。
インフラのバージョン管理が可能
Gitなどのコードのバージョン管理ツールと組み合わせることで、インフラのバージョン管理ができます。インフラを2つ前の状態に戻したい、というような場合でも容易に変更が可能です。
参考:*4
GitOpsとは
開発ツールであるGitを用いて、インフラの運用まで行ってしまおうという考え方です。インフラを変更する際は一度リモートリポジトリにpushしてからMerge Requestを出します。そして、Github Actionsなどを経由してIaCツールやCI/CDツールを動かし、インフラの変更を検証・適用します。
GitOpsで検索するとKubernetesのことが書かれた記事が多くヒットしますが、今回Kubernetesは触らなかったので言及は控えておきます。
メリット
インフラの状態が追跡可能
このメリットが圧倒的に大きいです。IaCによりインフラをコードとして管理できるようにはなりますが、複数の運用者がそれぞれのローカルから共通のインフラを自由にいじってしまうと、インフラの状態を追跡することが困難になります。GitOpsではインフラの変更履歴がGitに残るので、インフラの状態がいつ、どのように変更されたのか追跡が容易になります。
インフラ運用の安全性が向上
MRでレビュープロセスを経ることや、インフラの変更時にコマンドラインでの操作を減らすことで、インフラを安全に運用することが可能になります。これは、組織の考え方によるところもありそうです。
参考:*5
AWS DynamoDBについて
前提:DynamoDBなどのNoSQLが登場した背景
RDBMSが登場した1970~90年代当時は、まだインターネットが世界に普及していない時代だったため、データベースに求められることとしては厳密な一貫性(最新のデータを必ず参照できること)が主でした*6。
そのため、RDBMSは、トランザクションやバリデーションといった機能・仕様を採用しており一貫性が高い一方で、スケール性能(ここでは、スケールアウトのしやすさ)は高くありませんでした。
しかし、インターネット使用人口の増加や、デジタルで扱うデータの増加に伴い、大量のデータに大量のユーザが高速にアクセスするために、データベースのスケール性能が求められるようになりました。これに対しRDBMSではレプリケーションの機能を備えるなどしてスケール性能を上げてきていますが、一貫性を保証する以上書き込み用のインスタンスはスケールできないうえ、その部分が単一障害点となってしまうため、スケール性能や可用性の面で万全とは言えません*7 *8。
一方で、一貫性を諦める代わりにスケール性能や可用性を高めたデータベースも登場しました*9。これらが一般的にNoSQLと言われます。DynamoDBもその1つです。DynamoDBでは、デフォルトで結果整合性というモデルを採用しており*10、厳密な一貫性を捨てることによってレスポンスを高速化しています。
DynamoDBのデータ管理
RDBMSとの大きな違いであるスケール性能を解説するにあたり、DynamoDBのデータ管理方法を知っておくことは欠かせません。 ただ、データ管理の方法について解説する前に、DynamoDBのテーブルにおける主キーというものについて、もう少し詳しく知っておく必要があります。
DynamoDBのテーブルは基本スキーマレスなので、予め属性や型の定義を行う必要はありません。ただし、テーブル定義の際、単一の主キー(パーティションキー)か複合主キー(パーティションキーとソートキー)となる属性を必ず設定しておかなければいけません。
 さて、肝心のデータ管理方法ですが、DynamoDBでは1つのテーブルに対し、パーティションと呼ばれる物理ストレージを複数台用意し、それぞれにデータを小分けして保存することで分散管理を実現しています。
さて、肝心のデータ管理方法ですが、DynamoDBでは1つのテーブルに対し、パーティションと呼ばれる物理ストレージを複数台用意し、それぞれにデータを小分けして保存することで分散管理を実現しています。
それでは、各データを保存するパーティションはどのように決まるのでしょうか。ここで登場するのがパーティションキーです。パーティションキーの値を内部ハッシュ関数の入力とすることで、保存先のパーティションを決定しています。つまり、パーティションキーの値が同じデータは全て、同一のパーティションに保存されるということです。。
それでは、ソートキーとは何でしょうか。名前から察しがつく方もいらっしゃると思いますが、各パーティションでデータをソートする際の基準となるのがソートキーです。これを設定しておくことで、データはソートキーの値に基づいてソートされた状態で保存されます。
余談になりますが、先程タスクの説明の中で、クエリによる検索では非キー属性を検索条件に指定できないという話をしました。これはまさに、DynamoDBが主キーに基づいてデータを分散管理しているためです。もし非キー属性以外でクエリによる検索をかけたければ、セカンダリインデックスというものを作成する必要がありますが、話の本質とずれるのでここでの解説は省きます。
DynamoDBのスケール性能
さて、DynamoDBのデータ管理の方法が分かったところで、スケール性能について解説します。
AWS公式リファレンス*11では、以下のように記述されています。
DynamoDB は次の状況でテーブルに追加のパーティションを割り当てます。
プロビジョニングされたスループット設定とは、大体このぐらいのトラフィックが捌ければいい、という性能のことで、テーブルに対して事前に設定しておくことができます*12。サービスのユーザ数が増えてくるなどしてより高いスループット性能に変更した場合は、AWS側で自動でスケールアウトしてパーティションを増やしてくれるということです*13。
また、既存のパーティションが容量オーバーになった場合も、同様に自動でスケールアウトしてくれます。DynamoDBはフルマネージドのDBなので、自分たちで対応しなくても勝手にいい感じにやってくれるので便利ですね。
感想
1ヶ月はとても短かったですが、メンターさんをはじめ、チームの方々の手厚い指導のおかげで、短期間で多くのことを学んで帰ることができました。指導に手厚いだけでなく、入社して3日目の私をプライベートの集まりに読んでいただくなど、非常にフレンドリーに接してくださったので、勤務時にも安心して会話することができました。
余談ですが、インターン期間中にCAさんの選考も並行して進めており、Abema Towersの11Fで6Fにいる社員の方とリモートで面接したのはいい思い出です。
同じビルにいる面接官とリモートで面接するという面白いことしてきた
— いとゆう (@theforestofmus2) 2021年11月12日
おまけ
飯テロ注意。
美味しかった昼食ベスト3(全て肉)。食費面はたいへんお世話になりました、、



道玄坂付近のめっちゃファンシーなホテル

夏と秋のインターンでアベマくんが2つ揃った。同じように見えて、一方は固く、もう一方は柔らかい。

以上!!!お付き合いありがとうございました!!!!
*1:[レポート] AWS を活用したコンテンツ価値を最大化するABEMAのクラウド戦略 #interbee | DevelopersIO
*2:DynamoDB のグローバルセカンダリインデックスの使用 - Amazon DynamoDB
*3:DynamoDB でのクエリの使用 - Amazon DynamoDB
*4:Infrastructure as Code(IaC)とは?インフラをコー…|Udemy メディア
*5:CNDT2020シリーズ:オススメのGitOpsツールをCAのインフラエンジニアが解説 | Think IT(シンクイット)
*7:デジタル変革とデータベースのスケーラビリティ:NoSQLベストプラクティス(5)(2/2 ページ) - @IT
*8:RDBMSとNoSQLを徹底比較!特徴からそれぞれのメリット・デメリットまで、わかりやすく解説! | GeeklyMedia(ギークリーメディア)
*9:NoSQL登場の背景、CAP定理、データモデルの分類 - Publickey
*11:パーティションとデータ分散 - Amazon DynamoDB