休学して2度目の就活でWebエンジニアを目指したら強くてニューゲームだった件
 お久しぶりです。いとゆうです。
お久しぶりです。いとゆうです。
私自身の就活に関する話は本ブログではろくに触れていませんでしたが、この記事で初めて本格的に触れようと思います。
私の場合、もともとは22卒生としてWeb系企業をメインにエンジニア就活をしていたのですが、色々な要因が重なって満足のいく結果が出せず、休学して2度目の就活をすることを選びました。そして先日、第一志望であるWeb系メガベンチャーから内定をいただくことができたため、振り返りとちょっとの自己満足のために本記事を書くことにしました。
そもそもなぜ就活に失敗したのか
ここでは、なぜWebエンジニアとしての就活に失敗したのかという意味で書きます。 理由は主に2つあると考えています。
Web系企業の就活情報が圧倒的に不足していた
私は学部のときから情報系ではありましたが、悲しいことにWeb開発との接点は皆無でした(泣) 大学院に進学して環境が変わったことで初めて接点が生まれ、そこから研究や講義の片手間にハッカソンや個人開発をするようになり、徐々にその魅力に気づいていきました。
「Webエンジニアとして働きたい!よし、熱意や経験をアピールして頑張るぞ!」
と、意気込んだのが修士1年の秋。おわかりいただけただろうか。Web系の選考はとにかく時期が早く、早いところでは8月~9月くらいからエントリー受付が開始されます。つまり、完全に出遅れてしまったのです。
慌てて企業探しやらエントリーやらを済ませるも、書類落ち・技術面接落ちのオンパレード。ベンチャー企業をメインに受けていたのもありますが、Web開発の専門知識や実務レベルの開発経験に関する質問が当たり前のように飛んできて、新卒にそこまで要求するのか、と唖然としました。
自己分析のやり方が間違っていた
これは、2度目の就活を終えた今だからこそ実感できました。就活といえば自己分析が大事、みたいなところが一般的な認識としてありますし、私もそれは自覚して取り組んでいたつもりだったですが、今思えばやり方が間違っていたな、と思います。
具体的には、エントリーした企業のESや面接の質問に答えるために自己分析をしていました。例えば、A社の志望動機を書くために、A社に響くような自分の特性や過去の経験だけを記憶から引っ張り出してくる、といった具合です。本来であれば自己分析をして自分の行きたい業界・企業を決めてからエントリーするべきだったのでしょうが、完全に順番が逆転してました。
結果、自分の本心よりも企業ウケを前提にした仮想的な人物像が出来上がってしまいました。こうした人物像は場当たり的に作り上げたものなので一貫性がなく、面接などですぐにボロが出てしまいます。
例え内定まで進むことができたとしても、自分の本来の人物像がその会社に合わないのであれば、後から苦しい思いをすることになります。実際私も1度目の就活で2社ほど内定をいただいておりましたが、いざ冷静になると自分には合わないなと感じ、苦心の末どちらも辞退させていただきました(申し訳なかったです)。
休学中に何をしたのか
修士2年の5月から休学し、12月に内定をもらうまでの8ヶ月間、何をしていたのかをざっくり時系列で書いていきます。
5月:個人開発、自己分析、逆求人イベントへの参加
面接でさんざん痛感した技術力不足を補うため、まずは個人開発をはじめました。思えば、これまでWeb開発というものを体系的に学んだことがなかったため、一度基礎固めをしておいた方がよいと考え、以下のUdemyの講座を購入して典型的な掲示板アプリを作成しました。
DockerやRDBなど、Web開発において汎用性の高い技術についての基礎的な素養が身に付けられたのではないかと思います。
また、この時期から一応自己分析は始めていました。幸いなことに大学の友人が自己分析のやり方について助言をくれたため、以前のような過ちを犯すことはありませんでした。この時点ではまだ企業選びの軸までははっきりしていませんでした。
そして、逆求人イベントにも参加しました。企業について知り、あわよくばインターンのお誘いをもらおうと考えていました。このイベントで、内定先の御社との接点を作ることができました。
6月~7月:チーム開発、インターン応募
個人で掲示板アプリを作り終えた後は、友人に声をかけてチーム(といっても2人)でオリジナルのアプリを企画・開発しました。
↓こんな感じの、意見箱とToDoリストを融合させたサービスです。
 アプリ開発と並行して、とにかく就業型インターンに片っ端から応募しました。過去に受けた面接で実務的な観点の質問をしばしば問われ、新卒といえどある程度は実務よりの知見が求められていると感じたためです。とはいえ、インターンの選考でも技術力は問われ、
個人開発をちょっと経験したくらいの人間は容赦なく書類で落とされます。立て続くお祈りメールに心をへし折られそうになりながらも、どこかは拾ってくれると信じて応募を続けていました。
アプリ開発と並行して、とにかく就業型インターンに片っ端から応募しました。過去に受けた面接で実務的な観点の質問をしばしば問われ、新卒といえどある程度は実務よりの知見が求められていると感じたためです。とはいえ、インターンの選考でも技術力は問われ、
個人開発をちょっと経験したくらいの人間は容赦なく書類で落とされます。立て続くお祈りメールに心をへし折られそうになりながらも、どこかは拾ってくれると信じて応募を続けていました。
結果として、4社からオファーをいただき、日程の都合で1社は辞退して3社に参加させていただくことになりました。
8月~9月:インターン参加、インターン応募
夏は、休日を除けばほぼインターンで埋まりました。以下は参加したインターンの体験記です。
記事にもある通り、個人開発では意識することのなかった運用やアーキテクチャなど、実務的な知見を多く見に付けることができました。 また、インターン先の会社で定期的に人事面談を設定いただいたことで、自然と自己分析も進んでいきました。
インターン参加と並行して、秋以降のインターン応募も進めていました。秋以降は本選考が本格化するため、夏インターンほどの数は応募しませんでした。
10月:個人開発、逆求人イベントへの参加、本選考
インターンを終え、実務的な知識がいろいろと身に付いたところで、個人開発にもその知識を還元しようと思い、個人で新しいWebサービスの企画・開発をはじめました。これまではバックエンドを中心に経験を積んできましたが、実際の現場では技術領域をまたいでコミュニケーションや開発をすることも多い(企業や部署にもよる)と聞いたので、フロント開発にも取り組み始めました。結果、このサービスは未完に終わりましたが、後の選考でアーキテクチャを意識して書いたコードを評価していただきました。
そして、この時期から逆求人イベントに積極的に参加しはじめました。就活の軸もかなり解像度が高まってきていたので、軸にマッチした企業が多数参加している回を中心に申し込み、1年前に比べて面談スケジュールがぎっちりと埋まるのを見て確かな手応えを感じました。
逆求人やエージェントの紹介で興味をもった会社には、この時期から本選考のエントリーを始めました。また、夏のインターン経由での早期選考もスタートしました。
11月:インターン、本選考
運よく1ヶ月の就業型インターンが決まったため、11月は週3でインターン、週2で本選考という比率で進めていました。
はじめての対面型インターンで、1ヶ月を渋谷で過ごしました。社員との交流機会の多さや職場の雰囲気の感じやすさなど、リモートにはない魅力を体感しました。
本選考もインターン選考と同じスタンスで、とにかく数を受けていました。一方でインターン選考と違うのは、自分の就活軸や興味のある事業領域に多少なりともマッチする企業しか受けなかった点です。ありがたいことに逆求人や就活サイト経由で企業の方からオファーをいただくことも多かったのですが、軸に合わないと判断した場合はお断りしていました。
12月~1月:本選考、内定獲得
インターンが終わってからは本選考のみに集中していました。 相当に技術志向の強い会社以外は書類や技術面接で落とされることもなくなり、休学中の活動がたしかに評価されていると感じました。
メガベンチャー4社とスタートアップ2社の選考で最終面接まで到達し、うち2社内定、2社落選、2社選考辞退という結果になりました。
就活を振り返って
さて、ここからはWebエンジニアを目指す学生の方向けに、私が2度の就活を通して得た教訓をいくつか書いていこうと思います。
教訓1:自己分析は選考と切り離して行う
冒頭でも書きましたが、選考対策のための自己分析はおすすめできません。見えてくる人物像が断片的で場当たり的なものになり、自分の本心をなおざりにしてしまうためです。企業からよく見られようという思いは一度捨て、良い部分も悪い部分も隈なく分析してみることをお勧めします。
分析のしかたはいろいろあると思いますが、私は大きく2パターンの方法を用いました。
1つ目が、自分の幼少期から大学までの価値観や性格の変化を時系列で分析する方法です。自分がその時どんな人間で、どんな経験をし、それが自分の価値観をどう変化させたのかを、人生の各段階において振り返ります。こうすることで、自分がもともと持っている価値観や、成長過程で新たに獲得した価値観を洗い出すことができます。これは人事面接のかなり有効な対策になると思います。悪い部分も含めて認識しておくことで、面接でうっかりマイナスなことを口走ってしまうリスクも減ります。
2つ目が、ライフチャートという方法です。詳しい説明はネットでいくらでも出てくるので省きますが、自分がモチベーション高く働ける状態がどういうものかがある程度見えてきて、企業選びの軸が決めやすくなります。
教訓2:就活軸は判断基準や優先度まで決める
自己分析をして企業選びの軸が出てきても、その軸が企業選びの際に機能しなければ意味がありません。例えば「裁量が大きい」という軸を決めただけでは、どの企業がそれにマッチするかを判断することは難しいでしょう。「現場のエンジニアが技術選定や設計まで行う」「エンジニアが企画に意見できる」など、具体的(かつ、できれば定量的)な判断基準にまで落とし込んでおくことで、企業選びや企業間の比較がしやすくなります。さらに、どの軸をより重視するのかという「優先度」を設定しておくことで、より合理的な比較・判断に繋がります。
教訓3:面接内容は忘れないうちにメモる
面接は神経を使うイベントなので、終わった後は気が抜けてしまいます。ですがもう少し踏ん張って、面接の内容をメモしておきましょう。面接官のポジションや質問内容、それに対する自分の回答、面接官の反応などを、覚えている限り書き起こします。これを面接のたびに繰り返すことで、単純に面接の振り返りになるだけでなく、どんな質問が頻出か、どんな回答がウケやすいか、といった傾向が段々と分かってきます。これは自分の経験に裏付けられたものですから、ある意味最も信用できるデータと言えるでしょう。
教訓4:リモート面接ならではの利点を活かす
今後どうなっていくかは分かりませんが、私の場合はほとんどの面接がリモートでした。そこで、質問への回答をする際、面接官の許可を得て自分のポートフォリオサイトを画面共有しながら話したり、勉強に使用している本をカメラ越しに見せながら話したりしていました。おそらく口頭だけで話すよりも伝わりやすくなるので、こうしたリモートならではの利点は積極的に活用していくと良いと思います。
教訓5:とにかく実務を経験する
これは本当に大事です。Web系企業の技術面接は現場のエンジニアが担当することがほとんどです。はっきり言って、個人開発と実務開発では視野がまるで違うので、個人開発オンリーで面接に臨むと撃沈しかねません(1年前の私)。インターンやアルバイトなどで実務開発を経験しておくことで、面接官と目線をそろえられるだけでなく、Webエンジニアという職種についても理解を深めることができます。
ただ、個人開発の成果物もあった方がいいです。企業の内部で出した成果は外部公開がNGな場合も多く、せっかく良い経験をしていても面接官にアピールできない可能性があるためです。理想はまず実務を経験し、その知見を持ち帰って個人開発に反映することかなと思いますが、そもそも開発経験がないと実務で雇ってもらえないので難しいところです...
教訓6:逆求人を有効活用する
逆求人はWebエンジニア志望学生の強い味方です。うまく使えば、一日で複数の志望企業とコンタクトをとることができます。企業理解も進みますし、優遇がもらえたりしたら選考をかなり効率的に進めることができます。私は以下のサービスを使わせていただきました。
ただし運営会社によっては、全く興味のない企業との面談を組まれてしまうなんてこともあるので、リスクとリターンのバランスを考えながら応募しましょう。
Webエンジニア就活のために休学して感じたメリット・デメリット
ここまでは私のWebエンジニア就活の取り組みや教訓について話してきました。では、そのWebエンジニア就活において、休学という決断がどのような点でプラス、あるいはマイナスに働いたのかをお伝えします。
休学してよかったこと
開発スキルを格段に高められる
言わずもがなですね。学業を気にせず開発に集中できるので、スキルは格段に上がります。ただし、能動的に動くことは前提です。 学業や研究の予定を気にする必要もないので、就業型のインターンやアルバイトにもどんどん参加することができます。
もしあなたがWebエンジニアを目指しており、普段は学業などでなかなか開発ができないという場合は、休学を検討してみる価値はあると思います。
じっくり自分と向き合う時間がとれる
学業や研究と並行しながら就活をしていると、どうしても就活に割ける時間的・精神的リソースが限られてしまうため、自分と向き合うことを忘れがちです。そのため、自分に合わない企業を選んでしまったり、場当たり的な自己分析をしてしまったりする可能性があります(経験談)。
他のことから解放されて就活だけに集中できる環境を作ることで、自分と向き合って本質を見ることができ、本当に自分に合った企業・事業領域がどこなのか見定めることができます。
休学して辛かったこと
就活仲間がいない
私の場合、1人で休学に踏み切ったのでともに就活をする仲間がいませんでした。就活という心理的負担の大きいイベントで、その負担を分かち合う仲間がいないというのはきついものがありました。
1社でも内定が出るまでは気が抜けない
これは通常の就活でも言えることですが、休学をしたことでその緊張感はさらに増大しました。時間と費用をはたいて休学をするわけですから、何が何でも成果を出さなければというプレッシャーからは逃れられません。
とにかく数を受けて残機を増やしておくことは、こうしたプレッシャーを緩和してくれます。
復学したら研究室が変わっている
はい、これは私だけだと思います(笑)
自分が所属していた研究室が休学中になくなってしまい、別の研究室の所属になってました。 研究もまさかの0からリスタートです\(^o^)/
時代の流れというのは、かくも残酷なのか...
おわりに
私の就活の総まとめとして、本記事を書いてみました。これまでにバリバリ開発経験を積んできた人や、就活までまだ時間がある人にとっては、あまり参考にならない内容だったかもしれません。ですが、もし私と同じように就活が近くなってからWebエンジニアに興味をもった方がいれば、休学という選択肢は考えてみる価値があると思います。
Web業界は転職が多いので、自分の市場価値を高めるためにもファーストキャリアでどこに入るのかはかなり重要だと私は考えました。そのため、1度目の就活で内定をいただいた企業を辞退し、2度目の就活をすることを選びました。
Web系に行きたいという強い意志があり、能動的に動ける人にとっては、休学の期間はかなり有意義なものになると思います。一方で、プレッシャーや孤独感などの心理的負担に苛まれてしまうリスクもあります。自分の性格や境遇と相談して決断していただければと思います。
それでは最後に、私が休学する前に、休学経験者である私の友人から言われた言葉をそのまま送ります。
休学はいいゾ^^
最後まで読んでいただき、ありがとうございました!!!!
AbemaTVのインターンで動画データの管理コストを削減した話
 お久しぶりです.いとゆうです.
お久しぶりです.いとゆうです.
毎日寒くて嫌になります.京都の気候は,夏が暑くて冬が寒いというのはよく言われることですが,ほんとに住むには向かない場所だなぁ…とつくづく思います.私は寝起きの寒さにとことん弱い人間なので,起床時間の1時間前くらいに暖房を入れるようにしていますが,それでもお布団の呪縛から逃れるのは至難の業です.
さて,前置きはこのくらいにして,先日CyberAgentさんのインターン「JOB」に参加してきました.CAさんのインターンは夏にも参加させていただいたのですが,今回参加したJOBは実際の開発現場で1ヶ月働く就業型のインターンになります.勤務頻度は最低週3から選ぶことができ、私は就活と並行して進めたかったため週3で勤務しました。なので実質的な勤務日数は10日程度になります。
配属された部署
配属されるサービスや部署は,選考時にどんな経験がしたいかを伝えることで,それに合わせて決めてもらえます.私の場合は,「大規模なサービス」の「クラウドインフラ」を触りたいという希望を伝え,結果としてAbemaTVの動画運用の効率化や動画管理コストの削減を担っているContents Engineeringチームに配属となりました.
以下の内容は、Contents Engineeringチームの方々に許可をいただいて執筆しています。
AbemaTVのメディアアセット管理
今回担当したタスクについて説明する前に,まずAbemaTVの動画データやサムネイル画像などのメディアアセット(以後、アセット)の管理がどのようにして行われているかを説明する必要があります.
もともとAbemaTVでは,他社から納品,または自社で収録されたアセットを磁気テープに保存して管理していました.これがテレビ局でも一般的に用いられている管理方法だそうです.このようなアナログな管理方法をとっていた理由としては,クラウドストレージで管理しようとした場合の維持コストの大きさです.
しかし,コスト以外の冗長性や柔軟性なども含めて判断した結果,現在ではフルクラウドでの管理に移行してきています*1.
実際の管理方法について,詳しいことはお伝えできませんが,アセットを一元的に管理するための社内ツールが存在します.この社内ツール経由で,納品されたアセットをクラウドにあげて管理しています.
担当したタスク
さて,前節にて,クラウドでのアセット管理はコストがかかるということをお伝えしました.今回は,このクラウドでの管理コストを抑えるため,素材管理の社内ツール上でゴミ箱フォルダに投下されたアセットやフォルダ、およびそれらのメタデータを,投下から1週間経過後に削除するバッチの実装を行いました.大まかな仕組みは下図のようになります。
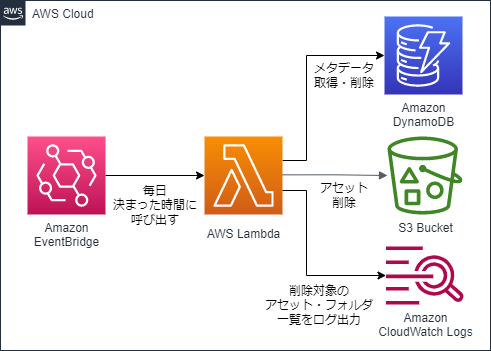
インフラ構築
上の構成図に沿って、AWSのインフラをTerraformで構築しました。Terraformは、JSONのようでJSONでないHCLというフォーマットで、AWSやGCPなどのインフラをコードとして構築できるツールです。
今回は、以下のリソースをTerraformで構築しました。
- EventBridge(Cloudwatch Event)
- Lambda
- ECR Repository(Lambdaのもとになるコンテナイメージのデプロイ用)
- IAM Role(LambdaにS3やDynamoDBへのアクセス権限を与えるため)
また、DynamoDBのテーブルに対し、グローバルセカンダリインデックス*2を新しく定義しました。この理由としては、主キー以外の属性に基づいて検索を行う必要があったためです。
DynamoDBの仕様上、テーブルに対してクエリで検索をかける際、非キー属性の値に基づいて検索をすることができません*3。今回、ゴミ箱投下から1週間以上経過したデータを検索するにあたり、非キー属性の値を条件として用いる必要がありました。
そこで、検索に用いたい非キー属性を主キーとしたグローバルセカンダリインデックスを新しく定義し、このインデックスに対してクエリを発行することで検索を可能にしました。
削除のロジック
アセット・フォルダを削除する際のロジックですが、これがなかなかに複雑でした。単純にクエリで取得したデータを削除して終わりではありません。
まず、DynamoDBに対してクエリを叩き、ゴミ箱フォルダに投下されてから1週間以上が経過したアセット・フォルダのメタデータを全て取得します。そこから更に、それぞれのアセット・フォルダの親フォルダを辿り、親フォルダもまた削除していいフォルダであるか(ゴミ箱投下から1週間経過しているか)を確認します。さらにその親フォルダを...と繰り返し、最終的にゴミ箱フォルダに行き着いた時点で、これまで辿ってきた親フォルダも含めてアセット・フォルダを削除します。
文字だけだと分かりづらいので、あるアセットAに対する削除ロジックを図解すると下のような感じです。

ここで、「なぜこんな複雑なことをするのか。クエリで取得した時点でゴミ箱の中に入っていることは分かっているのでは?」と思う方もいると思います。ここまで複雑な実装をする理由としては、メタデータに不整合がある可能性を考慮してのことでしょう。
例えば、私個人の推測になってしまいますが、一度ゴミ箱に入れたアセットを外に出した際、メタデータの更新がうまくいかずにステータス上はゴミ箱配下になってしまうケースです。クエリで返ってきたものをそのまま削除する実装だと、こうした不整合データを誤って削除してしまうリスクがあります。
学び
今回のインターンでは、経験の浅いクラウドインフラに関するタスクをメインに振っていただいたこともあり、インフラ面で多くのことを学ぶことができました。ここでは、下の3つのトピックについてまとめたいと思います。
- IaC、GitOpsという考え方について
- AWS DynamoDBについて
IaC、GitOpsという考え方について
IaC(Infrastructure as Code)とは
仮想化環境やクラウド環境においてインフラの定義をコードとして記述し、管理する考え方です。最近はクラウドインフラでサービスを運用するケースが増えており、サーバやデータベースといったリソースの実体を意識することが少なくなってきました。こうした背景を受け、リソースの実体を意識せずにインフラの設定や管理を効率的に行うための1つのプラクティスがIaCです。
運用者はリソースの構築や設定に必要な手続きを意識することなく、単に「このリソースを」「この設定で」用意したいと宣言的に記述していくことで、IaCのツールが自動的にインフラ構築を行ってくれます。分かりやすい例としては、Docker ComposeのComposeファイルです。実際はTerraformやCloudFormationといったクラウドインフラのIaCツールが用いられることが多いですが、Docker Composeも仮想化環境における1つのIaCの形だと思います。
resource "aws_instance" "web" {
ami = data.aws_ami.ubuntu.id
instance_type = "t3.micro"
tags = {
Name = "HelloWorld"
}
}
メリット
インフラの再現性が向上
手動でのインフラ構築は手順が煩雑化しがちなため、他者が同じインフラ環境を再現することは困難です。しかしIaCであればインフラを定義したコードを共有することで、他者でも容易に環境の再現が可能です。
インフラのバージョン管理が可能
Gitなどのコードのバージョン管理ツールと組み合わせることで、インフラのバージョン管理ができます。インフラを2つ前の状態に戻したい、というような場合でも容易に変更が可能です。
参考:*4
GitOpsとは
開発ツールであるGitを用いて、インフラの運用まで行ってしまおうという考え方です。インフラを変更する際は一度リモートリポジトリにpushしてからMerge Requestを出します。そして、Github Actionsなどを経由してIaCツールやCI/CDツールを動かし、インフラの変更を検証・適用します。
GitOpsで検索するとKubernetesのことが書かれた記事が多くヒットしますが、今回Kubernetesは触らなかったので言及は控えておきます。
メリット
インフラの状態が追跡可能
このメリットが圧倒的に大きいです。IaCによりインフラをコードとして管理できるようにはなりますが、複数の運用者がそれぞれのローカルから共通のインフラを自由にいじってしまうと、インフラの状態を追跡することが困難になります。GitOpsではインフラの変更履歴がGitに残るので、インフラの状態がいつ、どのように変更されたのか追跡が容易になります。
インフラ運用の安全性が向上
MRでレビュープロセスを経ることや、インフラの変更時にコマンドラインでの操作を減らすことで、インフラを安全に運用することが可能になります。これは、組織の考え方によるところもありそうです。
参考:*5
AWS DynamoDBについて
前提:DynamoDBなどのNoSQLが登場した背景
RDBMSが登場した1970~90年代当時は、まだインターネットが世界に普及していない時代だったため、データベースに求められることとしては厳密な一貫性(最新のデータを必ず参照できること)が主でした*6。
そのため、RDBMSは、トランザクションやバリデーションといった機能・仕様を採用しており一貫性が高い一方で、スケール性能(ここでは、スケールアウトのしやすさ)は高くありませんでした。
しかし、インターネット使用人口の増加や、デジタルで扱うデータの増加に伴い、大量のデータに大量のユーザが高速にアクセスするために、データベースのスケール性能が求められるようになりました。これに対しRDBMSではレプリケーションの機能を備えるなどしてスケール性能を上げてきていますが、一貫性を保証する以上書き込み用のインスタンスはスケールできないうえ、その部分が単一障害点となってしまうため、スケール性能や可用性の面で万全とは言えません*7 *8。
一方で、一貫性を諦める代わりにスケール性能や可用性を高めたデータベースも登場しました*9。これらが一般的にNoSQLと言われます。DynamoDBもその1つです。DynamoDBでは、デフォルトで結果整合性というモデルを採用しており*10、厳密な一貫性を捨てることによってレスポンスを高速化しています。
DynamoDBのデータ管理
RDBMSとの大きな違いであるスケール性能を解説するにあたり、DynamoDBのデータ管理方法を知っておくことは欠かせません。 ただ、データ管理の方法について解説する前に、DynamoDBのテーブルにおける主キーというものについて、もう少し詳しく知っておく必要があります。
DynamoDBのテーブルは基本スキーマレスなので、予め属性や型の定義を行う必要はありません。ただし、テーブル定義の際、単一の主キー(パーティションキー)か複合主キー(パーティションキーとソートキー)となる属性を必ず設定しておかなければいけません。
 さて、肝心のデータ管理方法ですが、DynamoDBでは1つのテーブルに対し、パーティションと呼ばれる物理ストレージを複数台用意し、それぞれにデータを小分けして保存することで分散管理を実現しています。
さて、肝心のデータ管理方法ですが、DynamoDBでは1つのテーブルに対し、パーティションと呼ばれる物理ストレージを複数台用意し、それぞれにデータを小分けして保存することで分散管理を実現しています。
それでは、各データを保存するパーティションはどのように決まるのでしょうか。ここで登場するのがパーティションキーです。パーティションキーの値を内部ハッシュ関数の入力とすることで、保存先のパーティションを決定しています。つまり、パーティションキーの値が同じデータは全て、同一のパーティションに保存されるということです。。
それでは、ソートキーとは何でしょうか。名前から察しがつく方もいらっしゃると思いますが、各パーティションでデータをソートする際の基準となるのがソートキーです。これを設定しておくことで、データはソートキーの値に基づいてソートされた状態で保存されます。
余談になりますが、先程タスクの説明の中で、クエリによる検索では非キー属性を検索条件に指定できないという話をしました。これはまさに、DynamoDBが主キーに基づいてデータを分散管理しているためです。もし非キー属性以外でクエリによる検索をかけたければ、セカンダリインデックスというものを作成する必要がありますが、話の本質とずれるのでここでの解説は省きます。
DynamoDBのスケール性能
さて、DynamoDBのデータ管理の方法が分かったところで、スケール性能について解説します。
AWS公式リファレンス*11では、以下のように記述されています。
DynamoDB は次の状況でテーブルに追加のパーティションを割り当てます。
プロビジョニングされたスループット設定とは、大体このぐらいのトラフィックが捌ければいい、という性能のことで、テーブルに対して事前に設定しておくことができます*12。サービスのユーザ数が増えてくるなどしてより高いスループット性能に変更した場合は、AWS側で自動でスケールアウトしてパーティションを増やしてくれるということです*13。
また、既存のパーティションが容量オーバーになった場合も、同様に自動でスケールアウトしてくれます。DynamoDBはフルマネージドのDBなので、自分たちで対応しなくても勝手にいい感じにやってくれるので便利ですね。
感想
1ヶ月はとても短かったですが、メンターさんをはじめ、チームの方々の手厚い指導のおかげで、短期間で多くのことを学んで帰ることができました。指導に手厚いだけでなく、入社して3日目の私をプライベートの集まりに読んでいただくなど、非常にフレンドリーに接してくださったので、勤務時にも安心して会話することができました。
余談ですが、インターン期間中にCAさんの選考も並行して進めており、Abema Towersの11Fで6Fにいる社員の方とリモートで面接したのはいい思い出です。
同じビルにいる面接官とリモートで面接するという面白いことしてきた
— いとゆう (@theforestofmus2) 2021年11月12日
おまけ
飯テロ注意。
美味しかった昼食ベスト3(全て肉)。食費面はたいへんお世話になりました、、



道玄坂付近のめっちゃファンシーなホテル

夏と秋のインターンでアベマくんが2つ揃った。同じように見えて、一方は固く、もう一方は柔らかい。

以上!!!お付き合いありがとうございました!!!!
*1:[レポート] AWS を活用したコンテンツ価値を最大化するABEMAのクラウド戦略 #interbee | DevelopersIO
*2:DynamoDB のグローバルセカンダリインデックスの使用 - Amazon DynamoDB
*3:DynamoDB でのクエリの使用 - Amazon DynamoDB
*4:Infrastructure as Code(IaC)とは?インフラをコー…|Udemy メディア
*5:CNDT2020シリーズ:オススメのGitOpsツールをCAのインフラエンジニアが解説 | Think IT(シンクイット)
*7:デジタル変革とデータベースのスケーラビリティ:NoSQLベストプラクティス(5)(2/2 ページ) - @IT
*8:RDBMSとNoSQLを徹底比較!特徴からそれぞれのメリット・デメリットまで、わかりやすく解説! | GeeklyMedia(ギークリーメディア)
*9:NoSQL登場の背景、CAP定理、データモデルの分類 - Publickey
*11:パーティションとデータ分散 - Amazon DynamoDB
CyberAgentさんの開発インターン「ACE」に参加してきました
こんにちは.夏休み中は専ら実家に入り浸り,親のすねをかじりまくっているいとゆうです.
基本的に実家周辺の気候は,自然豊かなこともあって夏でも比較的快適です.虫が多いのと,大雨のたびに土砂災害に警戒しなければならないことがたまにキズですが…
さて,タイトルの通り,先日サイバーエージェントさんの方で開発インターンに参加させていただきました.今回参加させていただいた「ACE」というインターンはCAさんにとって初の試みだったようで,前例がないため手探りな部分や不安要素もあったようです.ですが,僕個人としては非常に刺激的で学びの多い機会でした.今回は,CAさんのインターンで学んだことについて,「高品質なコードの書き方」という部分を中心に記事にしようと思います.
インターンの内容
今回のインターンは,現場のエンジニア社員から実務視点でのフィードバッグを受けながら,実務レベルの開発に挑戦するという点が特徴でした.3~4人でチームが組まれ,全チームが共通の要件に沿って開発を行いました.
本番の開発期間は3日間でしたが,その2週間前くらいには既にオリエンテーションが終了しており,そこから当日まではチームで自主的に開発を進めてください,という感じでした.本番の3日間で開発をする,というよりは,本番までにある程度のものを作っておいて,本番期間はレビュー→改善のサイクルをできるだけ回す期間,というスタンスでした.
ハッカソンなどとは異なり,作るものやその仕様については最初から明確に決まっており,今回は「ABEMAの番組表機能」を予め与えられた仕様に則って作成しました.
評価される項目としては「コードの可読性/保守性」や「耐障害性」「パフォーマンス」など実務で重視される部分が中心で,「オリジナルの機能の追加」や「UIの変更」などは評価しないことが明言されていました.本当に「実務的な開発」にフォーカスした内容でした.
使用した技術
私はバックエンドエンジニアとしての参加だったので,バックエンドとインフラに絞って書かせてもらいます.
バックエンド(Rest API)
本家のABEMAではバックエンドにgoが使われており,実際他のチームにはgoで開発をしているチームも存在しましたが,私たちのチームはnodejsで開発を行いました(ESとか面接でnodejsの経験をアピールしていたため).
nodejsで開発をするとなるとjavascriptかtypescriptか,という2択が生じますが,現状自分のtsの知識としては「あーあれね,型が決まるやつでしょ?」ぐらいのものだったので,まずはjsで書くことにしました.後々tsに書き換える?という話も一瞬浮上しましたが,学習コストと開発コストを割いてまで書き換えるほどのメリットがない,という結論になりそのままjsを採用しました.
使用したパッケージのうち代表的なものを下に書きます.
- express ... サーバ構築やルーティングに使用
- jest ... テストに使用
- swagger-jsdoc, swagger-ui-express ... APIドキュメントの自動生成に使用
- sequelize ... ORMとして使用
- eslint ... linterとして使用(後述)
ローカルでの開発/動作検証は基本的にDockerコンテナで行いました.
インフラ
インフラ環境はAWSで構築しました.「耐障害性」や「管理のしやすさ」というところが評価項目としてあったため,障害に強く管理しやすいインフラ構築が求められました.
僕自身のAWSの経験はというと,せいぜいdockerコンテナをEC2で立ち上げ,RDSに接続してアプリをデプロイしたくらいで,評価項目を満たす設計を考えろといわれてもピンときませんでした.
ありがたいことにインフラについてはCAの方が予め初期設計と構築をしたものを与えてくださり,構築されたインフラを眺めながらECSやALBといった初めての概念を吸収していくことができました.
インフラに強いメンターさんのアドバイスももらいつつ,既存のインフラに以下のような変更を施していきました.
- APIサーバをECSのFargate起動モードで起動
- 初期のインフラではAPIサーバをECSのEC2起動モードで起動していました.これをFargateに変更することで,低レイヤを意識する必要がなくなり管理がしやすくなるというメリットがあります.
- AuroraレプリカをAuto scalingに対応
- 初期のインフラではマスターとレプリカがそれぞれ1台という構成でした.CPUの使用率に応じてレプリカをAuto scalingさせることで,負荷分散を図りました.
- s3に番組表データの基になるjsonファイルを配置し,更新されるたびにラムダでDBに反映
- 本番用とテスト用のデプロイ環境を用意
他にもやりたいことは色々ありましたが,時間が限られていたこともあって断念…
学び
実務開発にフォーカスしたインターンということもあり,実務経験の乏しい私にとっては短期間で頭がパンクしそうなほど多くの情報が得られました.というか,終盤はほぼパンクしてました笑
今回は冒頭で宣言したとおり,「高品質なコードの書き方」に絞ってまとめていきます.
ただし,ここでいう高品質なコードとは,「可読性や保守/拡張性,あるいは開発効率の高いコード」を意味しています.これを前提として読んでいただければと思います.
アーキテクチャ設計
私はこれまでMVCモデルに基づいたバックエンド開発しか経験がなかったのですが,実務で開発するような大規模で長期的に運用していくことを前提としたサービスでは,事前にアーキテクチャ設計をよく練っておくことが大切であると分かりました.
私たちのチームは当初,serverファイルにルーティングもロジックもDB接続も全部書き込んでいました.実装すべきAPIの機能がそこまで多くなかったため,1ファイルにまとめてもそこまで煩雑にはならないだろう,という考えのもとでしたが,あくまで「実務を想定した」開発なので,今後機能の追加や仕様の修正があることを前提において設計を考えた方がいい,というアドバイスをメンターさんからいただきました.
他のチームはオニオンアーキテクチャやドメイン駆動設計など本格的なものを取り入れていましたが,1~2日でこれらの概念を理解し,実装まですることはさすがに厳しいと判断し,使い慣れたMVCをベースにビジネスロジックだけServiceに分離するMVC+Sを採用することにしました.
Serviceは初めて扱う概念で,最初はControllerとの役割の違いがいまひとつ分かりませんでした.いろいろと調べていく中で,以下のような理解に落ち着きました.
Controller
- リクエスト内容のバリデーション(パラメータが足りているか・適切なフォーマットか)を行う
- リクエストで受け取ったデータをServiceに渡せる形に加工して渡す
- Serviceが返したデータをViewに渡せる形に加工して渡す
Controllerはリクエストのバリデーションやデータのフォーマット変換など,サービスの実現したいコアな機能からは外れた部分の処理を書くイメージです.ViewとServiceを直接連携してしまうと,パラメータが不正だったりデータのフォーマットが扱いづらかったりして面倒なので,そこの橋渡しをControllerでうまくやってあげる感じです.
例えば今回,「指定した日付の番組データ一覧を取得する」という機能を実装したのですが,リクエストでUNIXタイムを受け取ってそれを日付に変換する仕様にしていました(フロントで日付に変換して渡す方がよかったかも).このUNIXタイム→日付の変換などは,機能とは直接関係のない部分なのでControllerに書くべき処理なのかなと思います.
Service
- そのサービス(今回の場合はAPIの各機能)が実現したい一連の処理を書く
- データの取得や更新など,データベースへのアクセスを行う(Repositoryとして分離するケースもある)
Serviceは,「番組表一覧の取得」や「番組の予約」など,サービスとして実現したい一連の処理を書くイメージです.ドメイン駆動設計では,アプリケーションサービスやドメインサービス,ドメインオブジェクトなどの更に細かい分類がありますが,ここではあくまで「機能を実現するためのビジネスロジックを全て書く場所」という位置づけにしています.
また,ドメイン駆動設計ではデータベースにアクセスする処理ををさらにRepositoryという形で分離していますが,ここではそれもServiceに含めています.ただし,Modelは別の階層で定義しており,Serviceではこれを呼び出してアクセスする形にしました.
ざっくり言うと「Controllerに書くべき処理以外は全てServiceに書く」という感じでしょうか.
アーキテクチャについてはまだまだ理解が浅いので,これから学んでいく必要がありそうです.ちょうど現在,他社のインターンでクリーンアーキテクチャについて学んでいるので,時間ができたらまた記事にしようと思います.
凝集度
オブジェクト指向開発において,コードの品質を評価するのによく用いられる指標のようです.これについては,CA社員の方がnoteに分かりやすくまとめてくださっているので,詳しい説明はそちらを参照していただければと思います.
クラスやメソッドといったまとまりにおいて,1つのまとまりにはできる限り1つの目的に沿った処理を書くことが,クラスやメソッドの再利用性やコードの可読性を高めることに繋がるのだと思います.記事にも書かれている通り,これは「クラスやメソッドをできる限り小分けする」ということではなく,あくまで「そのクラス(メソッド)がもつ意味を明確にする」ということです.
個人的に,「意味」は「価値」に置き換えられると思います.例えば,日付を指定して番組一覧を取得する機能を実装するうえで,日付を受け取ってDBから番組表一覧を取得するメソッドはたしかに価値があるといえます.このメソッドは内部的に日付をその日の0時を表すUNIXタイム(ミリ秒)に変換し,さらにそれを秒に変換し,Modelに渡すという処理を行っています.この1つ1つの処理をメソッドしておいたとき「日付をミリ秒に変換するメソッド」や「ミリ秒を秒に変換するメソッド」に価値を見出せるでしょうか.価値が見いだせないメソッドは,用途が曖昧なので再利用性が低いですし,無駄なメソッドばかり増えてもかえって可読性が損なわれると思います.
記事を読んでいて気になったのは,「論理的凝集」として定義されているIfによる分岐処理が極力避けるべきものであるという考えです.
記事の中ではIfとelseの中身をそれぞれ関数化しています.このようにして関数に分けたとしても,結局その関数の呼び出し元で条件分岐することになるのでは?と思います.論理的凝集を避ける理由として,機能追加があった場合に条件が増えたり複雑になることが挙げられているので,条件分岐が必要ないように(バックエンドであれば)エンドポイントを分ける,それでも条件分岐が生じてしまう場合は,Ifの内部で行っている処理は関数化してシンプルに記述できるようにする,といった対処になるのかな,と解釈しました.
凝集度の理解もなかなか苦労しそうです.併せて用いられる「結合度」という概念についても,コードを書きながら少しづつ理解していこうと思います.
変数への再代入を避ける
個人でコードを書くとき,私はこれを結構頻繁にやっていました.しかし,変数への再代入は,現在その変数に入っているものが何であるかを曖昧にし,コードの可読性を損なったりバグの原因になったりします.なので,できるだけ変数への再代入は避け,再代入したい場合は新しい変数(定数の方が望ましい)を定義するべきであると学びました.nodejsであれば,letやvarよりconstを使え,ということですね.
非常に分かりやすいですし,今後の開発で意識していこうと思います.
linterを使う
実務における開発では,1つのサービスを複数人で開発する場合がほとんどだと思います.その際,コードを書く人によって書き方の方式(例えば,インデントの大きさ,数値と演算子の間にスペースを入れるか,等)が違うと,サービス全体として統一感のないコードになってしまいます.
linterは,エディタに導入することで書き方の方式についての共通ルールを設定してくれます.linterに定められたルールにそぐわない書き方をしていると,エディタ上でそれを指摘してくれます.フォーマッタと組み合わせて用いることで,指摘だけでなく修正まで行ってくれます.開発メンバーで共通のlinterを用いることで自然と書き方が統一され,サービス全体として可読性の高いコードにすることができます.
今回はVSCodeで開発をしていたので,VSCodeの拡張機能として,javascriptのlinterであるESLintを導入しました.
使用する言語に合わせて,今後もlinterを導入していきたいところです.
おわりに
今回はコード品質に絞って書きましたが,他にも負荷分散やインフラ構築など学ぶことだらけのインターンでした.
実務の開発でどんなことが重視されているのかが分かったので,今後身に付けるべきものが明確になったと思います.
Web開発はまだまだ歴が浅くひよっ子ですが,就職する頃にはトサカのあるひよこぐらいにはなっていられるよう頑張ります笑
文字ばかりの記事でしたが最後までお付き合いいただき,ありがとうございました!
Windowsのクリップボードからwsl上のvimにコピペするのに苦労した話
久しぶりの,本当に久しぶりの更新です.
驚くことに,約9ヶ月のブランクが空いてしまいました.とくに更新の頻度を決めていたわけではありませんが,9ヶ月も空いてしまうとさすがに「怠惰か!」とセルフツッコミを入れたくなってしまいます.
勿論,この9ヶ月何もしていなかったわけではありません.ブログの方は放置しっぱなしでしたが,ハッカソンや就活,個人開発,果ては商談まで,色々と進めておりました.最初は単純に多忙で更新ができていなかったのですが,一度更新を止めてしまうと少々ばつが悪く,なかなか次の記事を書けないでいました.今回,久しぶりに記事にしたい内容が出てきたので,これを機に書いてみようと思います.
wsl上でvimを開いて,Windowsのクリップボードの内容をペーストしたい
wsl上でvimを使ってコードを書いていた際,Windowsのクリップボードの内容をそのままペーストしたいと思うときがありました.しかし, Ctrl+V は当然機能せず,ネットで調べた Shift+Insert のショートカットキーも効きませんでした.コピペできるようになるまでにいくつか障壁があったので,今回はその方法を記事にしようと思います.
環境は以下のとおりです.
問題点1:Shift+Insertが効かない
ネットで調べるとWindows環境では CTRL+V の代わりに Shift+Insert を使ってもクリップボードからペーストできると書かれていたのですが,wsl上のvimでこれを実行してもエディタ上に <S-Insert> と入力されるだけでペーストできません.
解決策
このIssueを参考に,wsl上のホームディレクトリ直下に.vimrcファイルを作成し,そこに
map! <S-Insert> <C-R>+
と記入し,キーのマッピングを行います. <C-R> は Ctrl+R の入力に対応し,vimの挿入モードでは貼り付けに対応します.また, + はクリップボードの内容を格納したレジスタで, <C-R>+ はクリップボードの内容を貼り付けることを意味します.わざわざ Shift+Insert をマッピングしなくても,挿入モードで Ctrl+R からの + を叩けば貼り付けできそうですね.
これで解決!かと思いきや,なぜかこれでもうまくいかず…
問題点2:そもそもクリップボードをvimと共有できていない
ノーマルモードで :reg と入力し,レジスタの一覧を見てみると, + がありません.wsl上で動かしているので,Windowsのクリップボードがvimから見えていないようです.
解決策
手順1:vim上でクリップボードを有効にする(いらないかも?)
wsl上で動いているvimがclipboard機能をサポートしていなかったので,このIssueを参考に以下のコマンドでパッケージをインストールするとclipboardが有効になります.
ただ,これはどうやらvim上でコピーした内容をWindowsなどのクリップボードに共有するための機能のようなので,今回は必要ないかもしれません.
apt-get install vim-gtk
手順2:VcXsrvをインストールし,XLaunchを実行する
ここからVcXsrvをインストールします.インストールが終了したら,スタートメニューからXLaunchを実行し,全てデフォルトの設定のまま起動します.これにより,ローカルでxサーバが立ち上がります.
手順3:wsl上で環境変数を設定する
xサーバを介してWindowsのクリップボードをwslのvimと共有するには,wslの環境変数 DISPLAY にwslのIPアドレスを設定する必要があります.こちらの記事を参考にwslのIPアドレスを取得し, DISPLAY 変数に格納します.具体的には,wslのホームディレクトリにある.bashrcに以下を追記します.
LOCAL_IP=$(ipconfig.exe | awk 'BEGIN { RS="\r\n" } /^[A-Z]/ { isWslSection=/WSL/; }; { if (!isWslSection && /IPv4 Address/) { printf $NF; exit; }}')
export DISPLAY=$LOCAL_IP:0
手順4:bashを再起動
wslを一旦抜けて入り直し,bashを再起動します.再度vimを起動し, :reg でレジスタ一覧を見ると + レジスタが追加されており,そこにWIndowsのクリップボードの中身が入っています.あとは,挿入モードで Shift+Insert や Ctrl+R & + を叩くだけです.
おわり
wslを使っているとメモリの枯渇や今回のような設定など苦労させられることが多いです.改めて開発におけるMacの偉大さを感じます.
参考資料
Inserting in insert mode inserts <S-Insert> · Issue #253 · equalsraf/neovim-qt · GitHub
How to copy text from vim to system clipboard? · Issue #892 · microsoft/WSL · GitHub
ASCII.jp:Windows Subsystem for LinuxのBashの初期設定【後編】
ハッカソン型インターンでどん底から這い上がって3位に選ばれた話
こんにちは。2ヶ月に及んだ夏休みが間もなく終わろうとしていることに焦る気持ちを抑えきれないいとゆうです。
夏休みに入る前、休暇中にやりたいことをあれやこれやとピックアップしておいたのですが、実際にはその半分くらいしかできませんでした。以前記事にしたサービスも、リリースするのにまだ時間がかかりそうです。自分の能力を過信してたなぁ…
さて、今回は私が9月下旬に参加した楽天株式会社様のインターンについて書こうと思います。楽天といえば楽天市場を筆頭に他のEC企業を圧倒するサービス数が売りのメガベンチャー企業です。今回参加したのは完全リモートのハッカソン形式インターンで、各チームに専属のメンターさんがつき、アイデア出しから開発、プレゼン資料作成までサポートしてくださいました。また、開発の合間に社員との談話会や職場紹介、個人単位でのキャリア面談などが設けられ、職場理解や進路相談にも手厚い態勢でした。何より嬉しいのがお給りょ…コホンコホン。
この記事の対象読者
- チーム開発の流れについてざっくりと知りたい方
- テーマに沿ったプロダクト開発のtipsを知りたい方
- オンラインの講義や会議に話者や聴衆として参加経験のある方
- 丸っこいものが好きな方

まずはアイデアソン
今回のインターンはハッカソン形式なので、まずはテーマが与えられました。テーマは今の時代らしく「オンラインで人と人をつなぐサービス」。このテーマに沿ってアイデアを出すところからスタートしました。
私たちのチームは全員M1の情報工学系で、なかには機械学習ニキもいたため、技術先行で考えようという話が出ました。また、他のチームが6人構成のところ、どういうわけかこのチームだけ4人構成であったので、アイデアで勝負しよう、という話も出ました。この2つの観点からアイデアをしぼっていきました。実現性やテーマとの親和性なども加味し、なんとかアイデアを2つまで絞ったのですが、そこから先が一向に絞れず…
絞れなかった理由としては、どちらに決まっても役割分担の際に一人余ってしまいそうだったからです。これがチーム開発の難しいところ。メンバー一人ひとりのスキルや経験をもとに適切にタスクをアサインしなければならないのですが、パズルピースのようにぴったりはまる配分方法が常にあるとは限りません。
結局、最後には実現性の部分を突き詰めて、アイデアを絞ることにしました。具体的な使用技術の検討をつけていく中で、片方のアイデアで使用を想定していたzoom APIの機能がzoomのpro版でしか使用できないことが分かり、こちらを切り捨てることにしました。
最終的に決まったシステムのコンセプトは、次のようなものです。
- ユースケース
- 多人数のオンライン会議や講義
- 問題点
- 上記のようなケースでは、映像が小さい、ビデオをoffにしている人が多いなどの理由により、話者が聴衆の反応を読み取りづらい
- 聴衆からすると、大人数になるほど自分の顔を晒すことに抵抗があり、ビデオをoffにしたい
- 解決策(2段階)

聴衆の映像をシンプルなアバターの動きに置き換えることで、zoomのギャラリービューなどで見た時にも一目で聴衆の反応が分かるというところが推しポイントです。その点で、既存のスナップカメラやLINEビデオ通話の機能などとの差別化をしています。
プロダクトデザイン
アイデアが決まったら、解決したい問題やターゲットなどを整理し、プロダクトの機能や画面遷移などを定義するプロダクトデザインのフェーズに入りました。アイデアソンの段階で細かい部分まである程度議論しておいたので、このフェーズはスムーズに進みました。と、思ったのも束の間。プロダクトデザインのプレゼンで、プロダクトマネージャの方からあからさまな不評をいただいてしまいました。

他のチームがそれなりにいい評価をもらっている中での不評だったので、なかなかに刺さりました。いただいたレビューのうち主要なものを抜粋すると、
- 話者が聴衆の反応を知りたいというニーズがそもそもあるのか分からない(利用シーンが狭いのではないか)
- 聴衆にとっての機能が何もないので、人と人をつないでいるとはいえない(テーマとの親和性が悪い)
というものでした。
1番目のレビューは完全に伝え方の問題でしょう。しかし、テーマとの親和性の部分は重視して議論を進めてきたはずであったので、2番目のレビューは正直驚きでした。私たちのチーム内では、人と人をつなぐという部分を通信的な意味で捉えていたのですが、どうやら社員の方が重視しているのは「インタラクション」だったようです。テーマの意味について、事前に社員の方とすり合わせをしておくべきでした…。かくして、私たちのチームはいきなりどん底に立たされてしまいました。

プロダクトデザインのレビューを受けて、いろいろと考え直さなければならないことが出てきました。一からアイデアを練り直している時間はないので、ベースは変えずに何か聴衆にとって役立つ機能を追加してインタラクティブ性を確保することを考えました。
オンライン会議や講義で聴衆が抱える問題を考えたところ、(主にオンライン講義で)聴衆からのアクションに話者が気付きづらいという点がが挙がりました。例えば、チャットなどで質問や指摘をしても、話者がすぐに気づいてくれるとは限りません。既存のビデオ通話ツールにはスタンプでのリアクションや挙手ができるものもありますが、スタンプは分かりづらい&一時的にしか表示されない、挙手は感覚的にできない&話者に気づかれにくいという欠点があります。

そこで、聴衆がリアルで手を挙げたことを検知し、映像に反映できれば利便性が上がるのではないかと考えました。後付け的になってしまいましたが、なんとかインタラクティブ性の問題は解決しました。
システムデザイン
システムデザインのフェーズでは、使用言語や技術、フレームワーク、開発環境などの詳細を決めるほか、メンバー毎の役割分担とラフスケジュールを決め、開発への備えを万全にしておきました。アイデア出しの時点で懸念されていた役割分担の問題ですが、私が他の所用で中抜けしている間に意外にもすんなりと決まっていました。大雑把な分担はこんな感じです。
| GUI | 感情推定・挙手検出 | アニメーション制作 | 仮想カメラ |
|---|---|---|---|
| Me | 機械学習ニキのDさん | 動画編集に強いHさん | 万能なKさん |
私は知らぬ間に、アプリの基幹部分であるGUIを任されておりました。

仮想カメラというのは、アバターのアニメーションをソースとした仮想的なカメラのことで、これをユーザの端末に認識させることで、zoomなどのビデオ通話ツールから利用できるようになります。
仮想カメラの作成にはOBS studioというネイティブアプリを使用し、このアプリを遠隔操作することで、ソースとなるアニメーションを私たちのアプリから動的に設定することにしました。正直、この連携部分は完全にKさん任せだったので詳細な説明はできかねます…参考までに使用したOBSのプラグインの情報を載せておきます。
ネイティブアプリと連携するという仕様上、開発するアプリもネイティブアプリ(ユーザの端末上で動作するアプリ)にする必要があります。ネイティブアプリなぞ私を含めてメンバーの誰も作った経験はなかったのですが、Kさんの情報によればnodejsのフレームワークであるElectronを使用することでWebアプリケーションと同じように作成できるのだそうです。チームメンバーの中で最もjavascriptの経験があるらしかった私は、その経験が活かせるのならとGUIの担当を承諾しました。
ここまで述べてきたシステムの概要をまとめると、次のようになります。

プロダクトデザイン同様、システムデザインもメンターさんの前でプレゼンし、フィードバッグをいただきました。主要なものを一部抜粋すると、
- 既存のものと自分たちで作るものの区別をはっきり示すこと
- スケジュールには遅れをカバーするためのbufferを設けておく
- ソフトウェアのバージョンやライセンスを明記すること
というものでした。
私たちのシステムはOBSや表情検出APIなど、既成品の力を借りる部分も大きいので、1番目のレビューは確かにその通りです。上記の概要図は、このレビューを受けて作り直したものになります。
2番目についても、納期に間に合わせるうえで大切なことであると納得しました。3番目は、当たり前と思う方もいらっしゃるかもしれませんが、私の中では新しい発見でした。チームで開発するうえで、他のメンバーが書いたコードを引っ張ってきて自分の環境で実行することはよくあります。この際、使用するソフトウェアのバージョンを揃えておくことで、バージョン違いによる動作不良などを防ぐことができます。そのため、ソフトウェアのバージョンについて明記しておくことは非常に重要です。
今回の開発ではnodejsとnpmのバージョンを予めそろえておきました。私の開発環境はWindowsだったので、Windows向けのnodistというバージョン管理ツールを用いてバージョンを揃えました。
開発
開発の下準備が整い、いよいよ開発がスタートです。
Kさんの提案により、githubを使ったissueドリブン開発をすることになりましたが、githubの使用経験が浅い私はどうすればよいのかさっぱりでした。周囲のメンバーもあまり分かっていなかったようで、Kさんのgithub講座が始まりそうな勢いでした。githubを用いたチーム開発の流れについては、それ単独で記事を書きたいくらい学ぶ必要性を感じたので今回は割愛します。
基本的には、各自黙々と開発を進めていきました。不慣れな技術を扱う場面も出てくるので、そのへんはお互いに聞き合いながら。自分では分からなくても、他3人いれば誰かは知っているというケースが多かったです。単独の開発では何時間も悩むような問題がものの数分で解決できてしまったりするのが、チーム開発のいいところですね。
しかし、OBSと私たちのアプリを連携させる段階で想像以上に時間がかかり、スケジュールにbufferを設けていたにも関わらずサービス残業に突入してしまいました。開発期間が限られている中で、チームメンバーの誰も触れたことのない技術を使ったことが災いしました。

開発最終日の夜に至っては、もはやインターンではなくハッカソンの徹夜開発を彷彿とさせる雰囲気でした(知らんけど)。奮闘の末、ようやくアプリが期待した動作をしてくれた時には、深夜にも関わらず大声を出してはしゃいでしまいました。
プレゼンテーション
英語力を重視する楽天らしく、プレゼンと質疑応答はAll Englishで行いました。プロダクトデザインでの反省を踏まえ、利用シーンが容易に想像できるような寸劇動画を導入に用いました。導入の流れは、
- 通常のオンライン会議や講義の様子を動画で見せる
- 開発物の紹介
- 開発物を使ったオンライン会議や講義の様子を動画で見せる
といった具合です。1の動画は肖像権の関係でお見せすることが難しいので、3の動画をお見せします。
あ、今更ですが開発物の名前は「emoTamaCamera(エモたまカメラ)」です。「感情(emotion)+玉(Tama)+カメラ(Camera)」からきています。語感がいいのでお気に入り。
online meeting with emoTamaCamera
online lecture with emoTamaCamera
エモたまカメラがある場合とない場合の対比で見せたことでユースケースを明確化し、lecutureの動画には生徒と教師がインタラクションをとる場面を盛り込むことでテーマとの親和性をアピールしました。
少々悩んだのがデモンストレーションです。上に掲載した動画が一種のデモンストレーションの役目を果たしているとも考えられますが、他の多くのチームはWebサービスを開発しており、リアルタイムで実際に動かしながらデモを行うことが想定されます。私たちとしても実際に動くものを作ったという証明のため、リアルタイムにデモを行いたい、という思いがありました。
しかしプレゼンの際に使用することになっているzoomウェビナーは話者の映像以外が表示されないため、感情推定や挙手検出のデモをリアルタイムで行うことは諦めざるをえませんでした。
代わりに、予め録画した以下の動画をデモとして流しました。GUI、ユーザの表情、アバターのアニメーションを一画面に表示したものです。が、肝心の表情は肖像権の関係で見せられずすみません…!
それでもやはり、実際に動くことを伝えたかったため、私たち自身がエモたまカメラを使ってアバターと化した状態でプレゼンを行いました。デモにこそなりませんが、聴衆に対するインパクトは大きかったと思います。
質疑応答は基本的に英語が得意なKさんにお任せしました。発表および質疑のクオリティも最終的な評価に関わってくるので、得意な人に一任するのは逃げではなく戦略です。
結果発表

総合評価3.5/5の、7チーム中3位でした。
機械学習やネイティブアプリなどの点が評価され、技術点では全チーム中最高の点数をいただきました。また、プロダクトデザインから一転して、テーマとの親和性の部分が評価されていることを何より嬉しく感じました。しっかりと議論し直して本当によかった!

一方で、パワーポイントや発表に対する評価が低いのは反省点です。動画や発表者のアバター化など工夫をしてはいたものの、開発に時間をとられてスライドの作成と発表準備がやっつけ仕事になっていた点は否めません。他のチームのプレゼンを聴いていると、スライドに発表に十分に時間をかけて準備してきたことが伺えました。成果を他人に理解してもらうためのものとして、やはりプレゼンの準備は疎かにしてはいけない部分であると痛感しました。
まとめ
今回の記事の中で、再現性がありそうな知見をまとめると
- 定められた期限の中で開発を行う際は、開発者がもつスキルとの相性や実現性をもとにアイデアを選ぶ
- テーマに沿った開発を行う際は、その意味について出題者側とすり合わせしておく
- 開発スケジュールをたてる際は、遅れが生じた際に備えてbufferを設けておく
- チーム開発では、使用するソフトウェアのバージョンは統一しておく
- チーム開発では、一人で悩んで解決しなかった問題はすぐに共有
- 言葉や文章で説明してもうまく伝わらないことはメディアにしする
- 開発と同じくらい、プレゼンも重要視する
ぐらいでしょうか。技術的なところに関する言及はほとんどできませんでしたが、もし要望があれば考えます。
また、開発に使用したgithubのリポジトリ情報も掲載しようか検討中です。ただ、私の一存で載せていいものでもないと思うので、載せるとしてもメンターさんの許可をいただいてからになると思います。
今回の記事は以上です。最後まで読んでいただきありがとうございました!

バックエンド初心者がPHPとMySQLでID&パスワード認証を実装してみた
こんにちは。とてつもなく暑い日々が続いていますね。僕は実家が山中にあるもので、帰省自粛の空気の中少しでも涼しい場所を求めてと帰省していましたが、山中ですら30℃を優に超える暑さでクーラーが手放せませんでした。クーラーつけるんなら帰省してもしなくても一緒だったな…
さて、記事の初投稿からなんと2ヶ月が経っていました。最初の記事であんなに偉そうにブログのメリットについて言っておきながら、自身が全くそれを体現できておらず、恥ずかしい限りです。一応の言い訳としては、講義のオンライン化による弊害で課題の量が例年に比べてえげつないほど多く、押し潰されそうになりながら格闘しておりました。入学前までは、「大学院の講義は楽単」なんて話を聞いていましたが、オンライン化という思わぬ例外によって完全に塗り替えられましたね。
さあ、そんな言い訳も夏休みに入ったのでもう通用しません。ということで随分とブランクがありましたが、2本目の記事を書こうと思います。
バックエンド初心者がPHPとMySQLを触ってみた
タイトルにもあるとおり、私いとゆう、これまでフロントエンドは多少いじってきたものの、バックエンドは全くの未経験です。バックエンドエンジニアのインターンを勢いで申し込んでみましたが、秒でお祈りメールが返ってきました。今どきは新卒採用でも技術や経験が求められる時代、世知辛い世の中です。
しかし嘆いてばかりはいられません。山のような課題から解放された今こそ、新しい技術を身に付けるとき…!ということで、この夏はバックエンドの技術を使ったWebサービスを作ってみることにしました。
サービスの詳細は形になった頃にでもまた記事にします(多分)。
バックエンド系の言語は色々あり何を使うか迷いましたが、Node.jsやpythonでは新鮮味がないかと思い今回はPHPを選択しました。そして、データベースはPHPと相性がいいとのことでMySQLで管理することにしました。
作りたいものの仕様(ざっくり)
ひとまずは、今回作りたいものの仕様をざっくりとまとめておきます。
<ルーム作成画面>
・8文字以上16文字以内の半角英数字をパスワードとして入力し、ルーム作成ボタンを押すことで固有のIDが割り振られたルーム(phpファイル)をサーバ上に作成する
・ルームIDはハッシュ化されたパスワードとともにデータベースに保存される
・ルーム作成完了画面には、このページを経由することでしかアクセスできない。
(正確には、アクセスしても強制的にルーム作成画面に飛ばされる)
<ルーム作成完了画面>
・ルーム作成画面から正式な手続きを踏んでルームを作成した場合にのみ移動する。
・ルーム作成完了の通知とともに、自動的に割り当てられたルームIDが表示され、ルーム入室ボタンを押すことでルーム入室画面へと移動する。
<ルーム入室画面>
・ルームIDとパスワードを入力し、ルーム入室ボタンを押すことで、IDが有効かつパスワードが正しい場合にのみルームのアドレスに飛ぶ。
・ルームには、このページを経由することでしかアクセスできない。
(正確には、アクセスしても強制的にルーム入室画面に飛ばされる)
<ルーム画面>
・ルームIDだけを表示するシンプルな画面。この部分を色々と作り替えていく予定。
いざ、実装
今回、初のPHPを用いたWebページの実装ということで、まずは効率的な開発ができる環境づくりから始めました。PHPはサーバサイドで動く言語なので、まずはサーバを立てない事には作成したファイルの動作を確認しようがありません。そこで、XAMPPというツールを用いてローカルサーバを立ち上げました。
↓こちらの記事を参考にしました。
超簡単!PHPプログラムをローカルで動作確認するための環境構築方法 | HPcode
XAMPPのモジュールにはMySQLも含まれているのでPHPの動作環境とともにデータベース構築のための環境も整えることができちゃいます。ちなみにデータベースの場合、ルートディレクトリは~\xampp\mysql\binになります。
ルーム作成画面(makeroom.php)

onsubmit="return checkForm()">
<div>
<input class='password-form-for-makeroom' id='password-form-for-makeroom' type='text'
name='password'>
</div>
</form>
テキストボックスとボタンの部分は<form>タグで囲んでいます。formタグのaction属性にデータを送信したいファイルのパスを設定することで、ボタンをクリックした際にそのファイルにデータを渡すとともに、遷移することができるんですね。
渡すデータは<input>タグのvalue属性に格納しておくようです。このinputタグ、変幻自在という感じで、type属性をtextにすることでテキストボックスに、submitにすることで送信ボタンになります。更にhiddenにするとユーザからは見えなくなります。hiddenはユーザーから見える必要のないものの送信に使われるようです。今回はページを開くと同時にCSRF対策のワンタイムトークンを生成し、これの送信に使用しています。
また、抜粋したソースコードには含まれていませんが、ワンタイムトークンはphpの連想配列$_SESSIONにも格納しておきます。$_SESSIONに格納されたデータはサーバに保存されるため、サーバ上であればファイルをまたいでも参照することができます。
↓参考にした記事はこちら
PHPでセッションを使う方法【初心者向け】 | TechAcademyマガジン
ルーム作成完了画面(makeroom_complete.php)

/* CSRF対策 */
$_SESSION['error_status']=1;
redirect_to_makeroom();
exit();
}
$password=$_POST['password'];
$roomid;
for ($i=10000;$i<=20000;$i++){
$result=mysqli_fetch_array(mysqli_query($link,'SELECT * FROM room WHERE id='.$i.' LIMIT 1;'));
if(empty($result)){
$roomid=$i;
break;
}
}
$hash=password_hash($password, PASSWORD_DEFAULT);
$result2=mysqli_query($link,"INSERT INTO room(id,password) VALUES(".$roomid.",'".$hash."');");
mysqli_close($link);
画面の構成はシンプルなのでルーム作成手続きの部分だけ抜粋しました。
まずはCSRF対策の部分から見ていきます。この部分の目的は、ルーム作成画面からのpost処理を介したアクセス以外を受け付けないようにすることです。
連想配列$_POSTには、先ほどのルーム作成画面のformタグから送信されてきたデータが格納されています。ここで重要なのが、$_POSTはルーム作成画面からpostされてきたデータであり、$_SESSIONはサーバに保存されているデータであるということです。つまり、$_SESSIONはサーバのデータが消えない限り値を保持し続けますが、$_POSTは他のページからのpost処理を踏んでこのページにアクセスしない限り空になるということです。ということは、$_POSTが空かどうか調べることで、ページへのダイレクトなアクセスは防ぐことができます。
さらに、ルーム作成画面以外からpostされてきた場合を防ぐには、$_SESSIONと$_POSTにそれぞれ保存されているトークンが一致するかどうかをチェックします。ルーム作成画面では$_SESSIONに保存したトークンと同一のものをpostしているので、正式なアクセスであればこれらは一致するはずです。これらが一致していないことは他のページからのアクセスを意味するため、拒絶します。
後者の条件は前者の条件を含んでいるので、後者についてのみ調べればOKです。
続いて、MySQLにデータを登録する部分です。ここでやりたいことは、固有のIDを割り当てたルームを作成し、ルームIDとパスワードをデータベースに保存することです。PHPとMySQLをつなぐインタフェースとしてはPDOというAPIが主流なようですが、今回は直観的な分かりやすさからmysqliを使用しました。
ルーム毎に固有のIDを割り当てる方法ですが、今回とっているのはいたってシンプルな方法です。設定するIDの範囲を10000~20000と決めておき、10000から順番に、そのIDが既に登録されているかどうかをデータベースを探索して調べます。登録されていなければそのIDを使ってルームを作成します。
ルームに設定するパスワードは$_POSTで送られてきているのでこれを使います。セキュリティの観点から、パスワードはハッシュ化して保存しておきます。
最後に部屋を作成する部分ですが、下記の記事を参考にしました。
フォームで入力した内容をhtml ファイルを自動生成しながらphpで埋め込むコード |うつ病ブログ
ルーム入室画面(enterroom.php)

基本的にルーム作成画面と実装方法は変わらないため、ソースコードは割愛します。ボタンをクリックすることで、入力されたルームID、パスワード、CSRF対策のワンタイムトークンをルーム入室完了ファイル(enterroom_complete.php)へpostします。
ルーム入室完了ファイル(enterroom_complete.php)
$roomid=$_POST['roomid'];
$password=$_POST['password'];
?>
</form>
<?php
$hash=mysqli_fetch_array(mysqli_query($link,'SELECT password FROM room WHERE id='.$roomid.' LIMIT 1;'));
if(!empty($hash)){
if(password_verify ( $password , $hash['password'] )){
echo '<script>document.token.submit();</script>';
exit();
}else{
$_SESSION['error_status']=2;
redirect_to_enterroom();
exit();
}
}else{
$_SESSION['error_status']=3;
redirect_to_enterroom();
exit();
}
このファイルはIDとパスワードの認証およびルームへのアクセスに用いられるため、ユーザに見せるための画面は存在しません。
各ルームへはこのファイルからのpost処理を介してしかアクセスできないようにするため、ここでもワンタイムトークンを設定しています。今まではボタンを押すことでpost処理をしていましたが、今回はパスワードの認証が終わり次第post処理を行います。
formタグのname属性に登録した名前でjavascriptのオブジェクトが作成されており、そのsubmitメソッドを呼び出すことでpostが行われるようです。
認証が失敗したり、ルームIDが登録されていなかったりした場合には、エラーコードを設定するとともにルーム入室画面へ強制的に移動します。
ルーム画面("ルームID".php)

まあ…わざわざ画像のせるまでもないですが(笑)
動かしてみる
バックエンドが少しでも触れるようになったことで実装できるものの幅がぐんと広がった気がします。
信用性を担保するならフレームワークとかAPIとかもっと使った方がいいんだとは思いますが、仕組みを理解するためにもまずは素朴に開発を進めようと思います。
自己紹介
はじめまして.いとゆうと申します.
最近書店でアウトプットの重要性を主張する本によく出会うので,自分も何かしらの形で普段学んでいる知識をアウトプットする習慣をつけたい!と秘かに思うようになりました.
この記事を書いているということはつまり,最終的にはブログという形を選んだわけです.しかしなぜ?私は自称合理主義者なので,自分にとって最もメリットが高いと思って選んでいるのですが,その具体的なメリットを列挙してみます.(おい,自己紹介どうした!)
ブログを通したアウトプットのメリット
- 分かりやすい文章を書こうという意識がはたらく→説明力がつく
- 文章にして伝えることで,語彙力や文法力がつく
- 続きやすい(このブログの更新が途絶えたときは撤回します)
- 手軽に,ある程度自分のタイミングでアウトプットできる
- アウトプットできる内容の自由度が高い
上3つは,不特定多数の人が見るかもしれないブログだからこそ得られるメリットだと思います.2つ目は日記やノートなども該当しますが,僕の性格的に日記やノートは"自分さえ見て分かればいい"という基準で書いてしまいそうなので不向きだと考えました.4つ目,5つ目のメリットである,手軽さや内容の自由度はやはり外せません.勉強会を開くのはハードルが高いし,教育系のバイトをしてもアウトプットできる内容には制限がありますから.手軽に,自由度の高いアウトプットができるツールは他にも様々ありますが(日記やノート,SNSなど),先述した上3つのメリットを同時に兼ね備えているツールは珍しいのではないでしょうか.ブログは,書き手に緊張感を与えて文章力を養ってくれるうえに,自分のタイミングで自分が望んだ内容を効率的にアウトプットできる数少ないツールなのです.
今更ながら自己紹介
偉そうなこと言って,お前何様だよ!と思った方もいらっしゃると思います.はい,では自分が何者なのか少しお伝えします.
私はこういう者です.
- 京大院の情報学研究科M1(なお学部生のときの大学は…)
- 機械学習,コンピュータビジョンを用いた研究に従事
- 夢見がちな性格,ゆえに現実との乖離にショックを受けがち
- 無類のチーズ好き
上2つのインパクトがかなり強いかもしれませんが,()書きにもあるとおり私は純粋な京大生ではなく,機械学習やコンピュータビジョンなんか院に入って始めたばかりのひよっ子です.ゆえに自分がこの分野を学んでいくうえで躓いた箇所を重点的に記事にできればと思っています.また,現在絶賛就活中ということもあり,就活関連でも自分の経験で参考になりそうなことがあれば記事にしていく予定です.
そんなこんなで,一本目の記事を何とか書き終えられそうでほっとしています.ブログを通したアウトプットが習慣化することを願うばかりです.
どうぞよろしくお願いします( _ _ )